
Nei dieci anni dal mio racconto iniziale ho continuato a lavorare nel campo della Bioinformatica presso l’Università della Pennsylvania (Upenn) a Filadelfia. Il centro interdipartimentale di Bioinformatica di tale università(PCBI) è stato soppiantato dall’Istituto di Informatica Biomedica (IBI) che lo integra comprendendo, oltre alla Bioinformatica, anche l’Informatica Medica, cioè l’informatica applicata alla gestione e analisi di dati clinici. Il mio lavoro tuttavia continua a incentrarsi sulla Bioinformatica, dunque sulla gestione, ma soprattutto analisi di dati di biologia molecolare. Sempre in questo settore, da due anni a questa parte sono anche coinvolta in un progetto con l’attiguo Children’s Hospital Of Philadelphia (CHOP) nell’ambito della Spatial and Functional Genomics Initiative (SFGI) con l’incarico di sviluppare e applicare opportune “pipelines” di analisi per i dati generati dai laboratori afferenti a tale iniziativa.
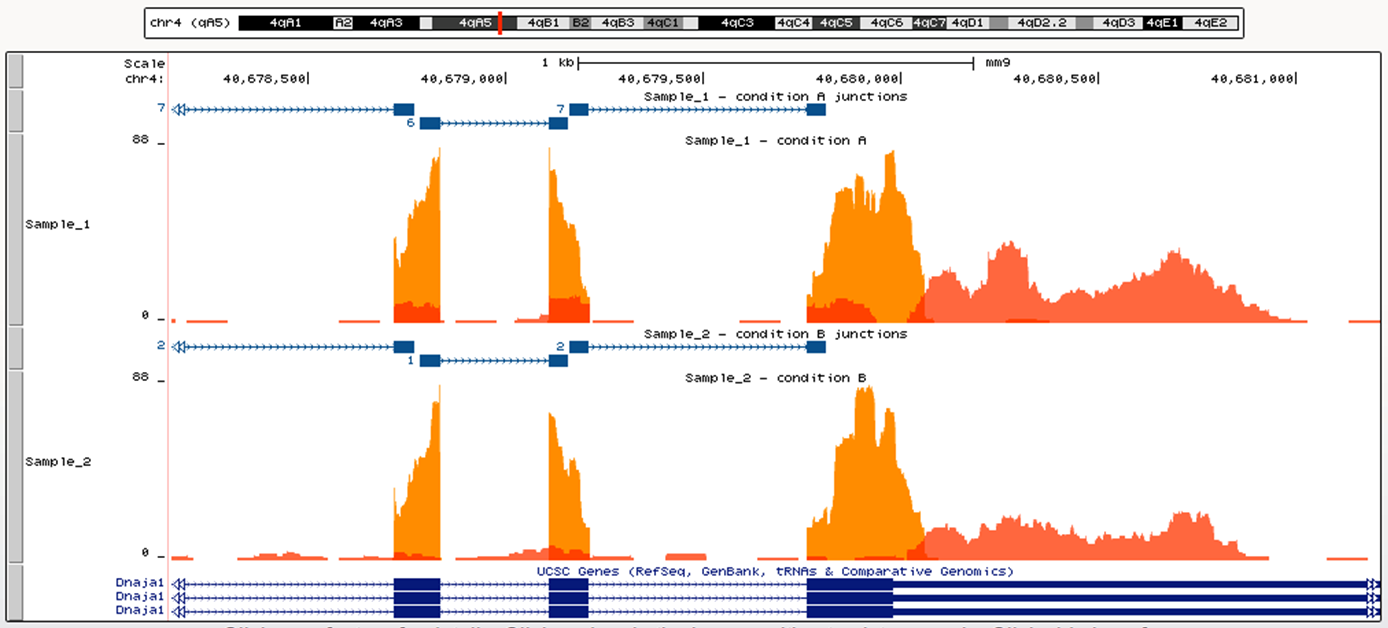
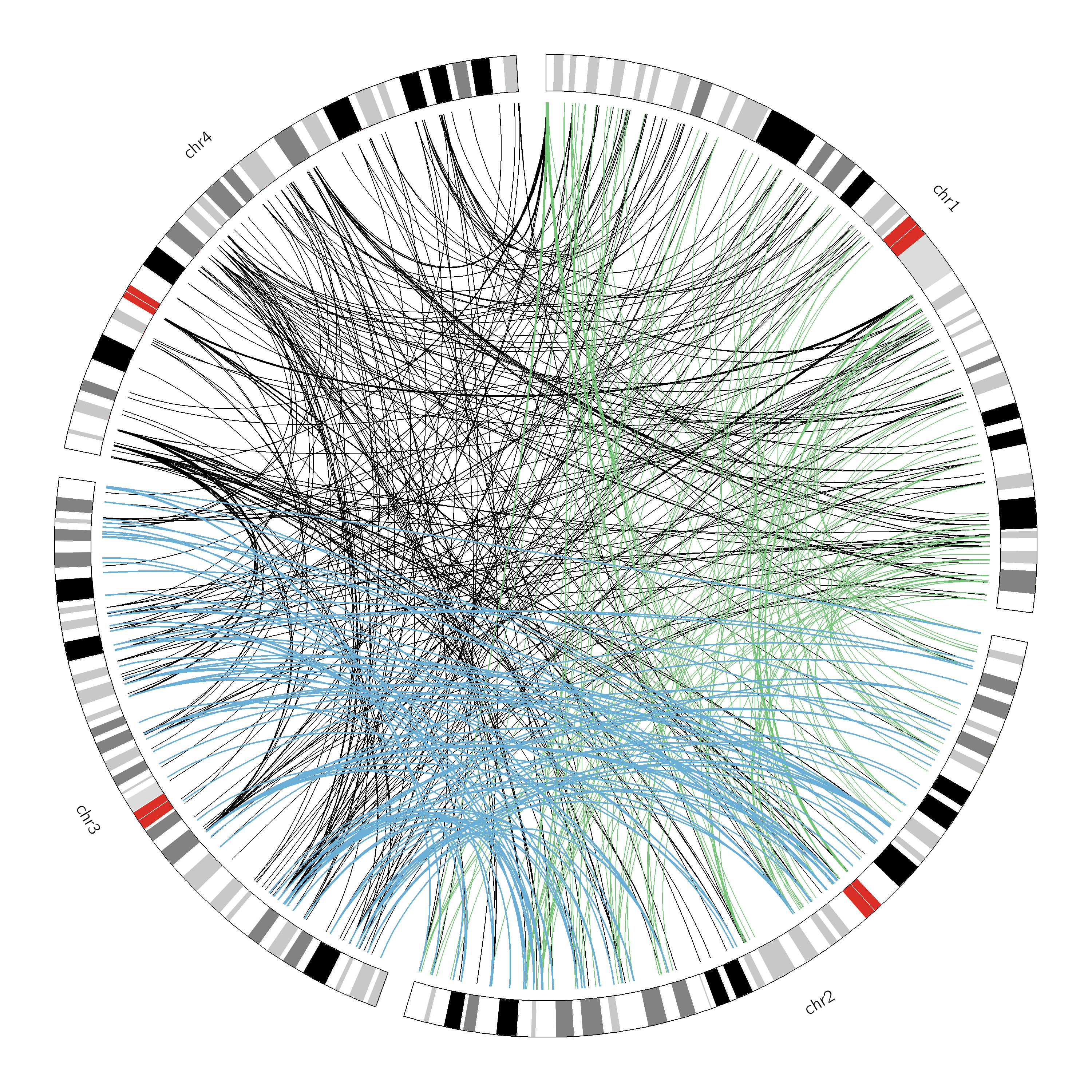

L’ultimo decennio ha visto un simbiotico evolversi sia delle nostre conoscenze sulle complesse reti biologiche che regolano il funzionamento delle cellule viventi, sia delle tecnologie a elevato rendimento ( “high-throughput”) che ci permettono di ottenere dati atti a studiare tali reti. Per esempio, l’avvento e la continua evoluzione di numerosi esperimenti basati su Next Generation Sequencing (NGS), cioè sequenziamento ad alta produttività di frammenti di molecole di DNA o RNA, nonché la riduzione dei costi di tali metodi, hanno contribuito al loro utilizzo sempre più esteso nei laboratori del settore. Dal punto di vista computazionale questo ha dato un’ulteriore slancio al continuo sviluppo di metodologie e algoritmi adeguati alla gestione e analisi del vasto numero di dati che ne conseguono. Le metodologie di analisi per un particolare tipo di tecnologia non sono quasi mai statiche perché man mano che più dati di tal tipo vengono analizzati si scoprono nuovi aspetti che vanno tenuti in considerazione per rendere i risultati più accurati.
È necessario un dialogo continuo fra i ricercatori che si occupano della parte sperimentale e i bioinformatici che devono analizzare i risultati di tali esperimenti per definire in maniera appropriata sia i metodi di pulizia e preparazione dei dati, tenendo conto delle distorsioni (“biases”) relative alla tecnica sperimentale usata, sia i metodi di analisi dei dati, in base al tipo di quesiti biologici e medici cui si vuole rispondere usando tali dati. Personalmente trovo l’interazione continua con biologi, genetisti e medici particolarmente interessante e stimolante. Questa mi ha permesso di apprendere molti aspetti all’avanguardia della biologia molecolare e della genetica anche se durante il corso dei miei studi universitari non avevo frequentato alcun corso afferente a questi campi.
Grazie al continuo sviluppo di tante nuove tecnologie a elevato rendimento atte a esaminare diversi aspetti molecolari e genetici, ha preso sempre più piede in bioinformatica lo sviluppo di metodi atti a integrare questi dati di diverso tipo per identificare con più precisione i meccanismi alla base dei complessi sistemi di regolazione dei geni nei diversi tipi di tessuti e cellule. Per esempio, recentemente diversi Genome Wide Association Studies (studi basati su uno dei tanti tipi di dati a elevato rendimento che possono essere generati) hanno permesso di individuare varianti genetiche associate a varie malattie complesse. Il passo successivo di rilevanza terapeutica è quello di determinare, per una data malattia, quali di queste varianti sono causali e per quest’ultime qual è il meccanismo che determina tale effetto. Il progetto in cui sono coinvolta presso CHOP ha come scopo, appunto, studiare questo tipo di problema avvantaggiandosi di altri dati a elevato rendimento atti a elucidare processi genomici di diversa natura.
Nel corso degli ultimi anni sempre più università negli Stati Uniti hanno istituito programmi di Bioinformatica sia a livello di laurea, che di master e dottorato. Per la natura di tali programmi tuttavia gli studenti devono seguire una varietà di corsi diversi, solo pochi dei quali di stampo prettamente matematico o statistico. Dunque spesso accade che chi invece ha fatto studi di Matematica è molto avvantaggiato per quel che concerne il vero e proprio sviluppo di metodi di analisi e può acquisire con velocità le nozioni necessarie per diventare produttivo in bioinformatica. Chi non ha avuto modo di imparare e approfondire il rigore analitico cui un corso di studi in matematica prepara, pur essendo in grado di utilizzare metodi di analisi bioinformatica sviluppati da altri, può avere molte più difficoltà nello sviluppare metodi nuovi o anche nel solo valutare la validità dei metodi altrui. Dunque, per esperienza personale, consiglio altamente agli studenti che hanno un’attitudine per la matematica a seguire senza esitazioni questa loro passione perché ciò fornirà loro basi solidissime anche per ricerca in altri settori molto diversi.
Dopo essermi laureata in Matematica presso l´Università di Roma 'La Sapienza' nel 1987, ho frequentato per un anno l´Istituto di Alta Matematica Francesco Severi.
Nel 1988 ho ottenuto una borsa di Teaching Assistant presso l´ Università del Maryland a College Park, USA, dove ho iniziato il corso di studi per il Ph.D. in Matematica, insegnando simultaneamente come esercitatrice di vari corsi (Calcolo I e II, Algebra Lineare, ecc.). Dopo aver terminato il dottorato sotto la guida del Professor David Rohrlich con una tesi nel campo della Teoria dei Numeri Algebrica, ho ottenuto una posizione di post-dottorato come Lettore in Matematica presso l´Università della Pennsylvania (Upenn) di Filadelfia. Come post-doc ho insegnato vari corsi di base, come Calcolo, e corsi più avanzati come Algebra Astratta e Teoria dei Numeri e ho continuato le ricerche intraprese durante il dottorato.
Finito il mio incarico presso il Dipartimento di Matematica di Upenn, ho lavorato per due anni come professore visitatore presso il Dipartimento di Matematica del College di Haverford, vicino a Filadelfia.
Nel 1998, in seguito ad un incontro e successive collaborazioni con professori di Upenn, che lavoravano nel campo allora nuovissimo della Bioinformatica, mi sono lanciata in questo settore, dando una svolta sostanziale alla mia carriera e passando dalla ricerca in Teoria dei Numeri a un campo molto più applicato. La Bioinformatica, ora una disciplina molto più sviluppata con tanto di corrispondenti corsi di laurea in varie università statunitensi, è nata in risposta a nuove tecnologie di biologia molecolare che hanno rivoluzionato in gran parte il modo in cui si svolge la ricerca in tale settore.
Queste tecnologie cosiddette “high throughput” permettono di fare esperimenti che generano un´enorme quantità di dati (e.g. dati di sequenziamento di genomi, dati di espressione genica, ecc.) che un biologo non può esaminare individualmente. Per esempio, invece di esaminare un gene specifico, questi esperimenti possono esaminare in parallelo migliaia di geni.
È dunque necessaria una stretta collaborazione fra biologi e medici che generano i dati e coloro che hanno l´esperienza computazionale per poterli gestire e analizzare, sviluppando appropriati sistemi di banche dati e algoritmi e metodi statistici. Nonostante i miei studi non avessero incluso corsi di statistica o di informatica, la mia formazione matematica ha senz´altro facilitato l´apprendimento rapido di ciò che mi serviva per poter lavorare in Bioinformatica. Come tipo di ricerca quest´ultima è spesso euristica. Quello che la rende particolarmentee interessante è la rilevanza medica e biologica dei problemi affrontati.
Dal 1998 lavoro presso il Centro interdipartimentale di Bioinformatica dell´Università della Pennsylvania (PCBI). Il nostro gruppo ha strette collaborazioni con laboratori, anche di altre istituzioni, che fanno ricerca in vari settori biomedici. Le ricerche riguardano sistemi diversi, dal pancreas e diabete al plasmodio della malaria, da studi sull´aterosclerosi a studi su traumi cranici, ma che generano dati dello stesso tipo e che possono dunque essere gestiti ed analizzati con metodi simili. Ogni progetto ha carattere interdisciplinare perché coinvolge personale proveniente da settori diversi come biologi e medici, statistici e matematici, informatici e ingegneri del software, e questo arricchisce il lavoro con scambi molto stimolanti.







